 Home-theater-designers
Home-theater-designers
Som dataanalytiker vil du ofte stå over for behovet for at kombinere flere datasæt. Du bliver nødt til at gøre dette for at fuldføre din analyse og nå frem til en konklusion for din virksomhed/interessenter.
Det er ofte udfordrende at repræsentere data, når de er gemt i forskellige tabeller. Under sådanne omstændigheder beviser joins deres værd, uanset hvilket programmeringssprog du arbejder på.
MAKEUSE AF DAGENS VIDEO
Python joins er ligesom SQL joins: de kombinerer datasæt ved at matche deres rækker på et fælles indeks.
Opret to datarammer til reference
For at følge eksemplerne i denne vejledning kan du oprette to eksempler på DataFrames. Brug følgende kode til at oprette den første DataFrame, som indeholder et ID, fornavn og efternavn.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)For det første trin skal du importere pandaer bibliotek. Du kan derefter bruge en variabel, -en , for at gemme resultatet fra DataFrame-konstruktøren. Giv konstruktøren en ordbog, der indeholder dine nødvendige værdier.
Vis endelig indholdet af DataFrame-værdien med printfunktionen for at kontrollere, at alt ser ud, som du ville forvente.
På samme måde kan du oprette en anden DataFrame, b , som indeholder et ID og lønværdier.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)Du kan kontrollere outputtet i en konsol eller en IDE. Det skal bekræfte indholdet af dine DataFrames:
Hvordan er sammenføjninger forskellige fra fletfunktionen i Python?
Panda-biblioteket er et af de vigtigste biblioteker, du kan bruge til at manipulere DataFrames. Da DataFrames indeholder flere datasæt, er forskellige funktioner tilgængelige i Python for at forbinde dem.
hvordan man tjekker grafikkort på windows 10
Python tilbyder sammenføjnings- og fletfunktionerne, blandt mange andre, som du kan bruge til at kombinere DataFrames. Der er en markant forskel mellem disse to funktioner, som du skal huske på, før du bruger dem.
Sammenkædningsfunktionen forbinder to DataFrames baseret på deres indeksværdier. Det flettefunktion kombinerer DataFrames baseret på indeksværdierne og kolonnerne.
Hvad skal du vide om joinforbindelser i Python?
Før du diskuterer de tilgængelige typer joinforbindelser, er her nogle vigtige ting at bemærke:
- SQL joins er en af de mest grundlæggende funktioner og minder ret meget om Pythons joins.
- For at deltage i DataFrames kan du bruge pandas.DataFrame.join() metode.
- Standardsammenføjningen udfører en venstre joinforbindelse, hvorimod flettefunktionen udfører en indre joinforbindelse.
Standardsyntaksen for en Python-join er som følger:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Kald joinmetoden på den første DataFrame og send den anden DataFrame som dens første parameter, Andet . De resterende argumenter er:
- på , som navngiver et indeks at deltage på, hvis der er mere end et.
- hvordan , hvilken definerer sammenføjningstypen, inklusive indre, ydre, venstre og højre.
- lsuffiks , hvilken definerer den venstre suffiksstreng i dit kolonnenavn.
- rsuffiks , hvilken definerer den højre suffiksstreng for dit kolonnenavn.
- sortere , hvilken er en boolsk værdi, der angiver, om den resulterende DataFrame skal sorteres.
Lær at bruge de forskellige typer sammenføjninger i Python
Python har et par tilmeldingsmuligheder, som du kan udøve, afhængigt af timens behov. Her er jointyperne:
1. Venstre Join
Den venstre join holder den første DataFrames værdier intakte, mens den bringer de matchende værdier fra den anden. For eksempel, hvis du vil hente de matchende værdier fra b , kan du definere det som følger:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Når forespørgslen udføres, indeholder outputtet følgende kolonnereferencer:
- ID_venstre
- Fnavn
- Lnavn
- ID_right
- Løn
Denne join trækker de første tre kolonner fra den første DataFrame og de sidste to kolonner fra den anden DataFrame. Den har brugt lsuffiks og rsuffiks værdier for at omdøbe ID-kolonnerne fra begge datasæt, hvilket sikrer, at de resulterende feltnavne er unikke.
Udgangen er som følger:

2. Right Join
Den højre join holder den anden DataFrames værdier intakte, mens den bringer de matchende værdier fra den første tabel. For eksempel, hvis du vil hente de matchende værdier fra -en , kan du definere det som følger:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)Udgangen er som følger:
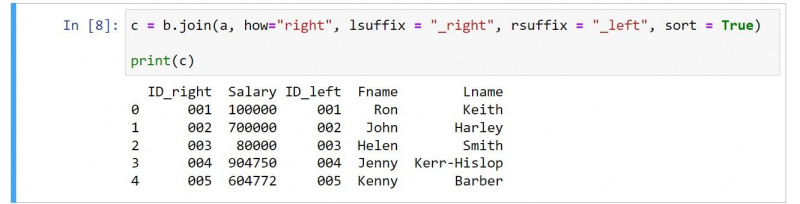
Hvis du gennemgår koden, er der et par tydelige ændringer. For eksempel inkluderer resultatet den anden DataFrames kolonner før dem fra den første DataFrame.
Du skal bruge en værdi på ret for hvordan argument for at angive en rettighedssammenføjning. Bemærk også, hvordan du kan skifte lsuffiks og rsuffiks værdier, der afspejler arten af den rigtige sammenføjning.
I dine almindelige joinforbindelser kan du finde dig selv ved at bruge venstre, indre og ydre joins oftere sammenlignet med højre joins. Brugen afhænger dog helt af dine datakrav.
3. Indre Sammenføjning
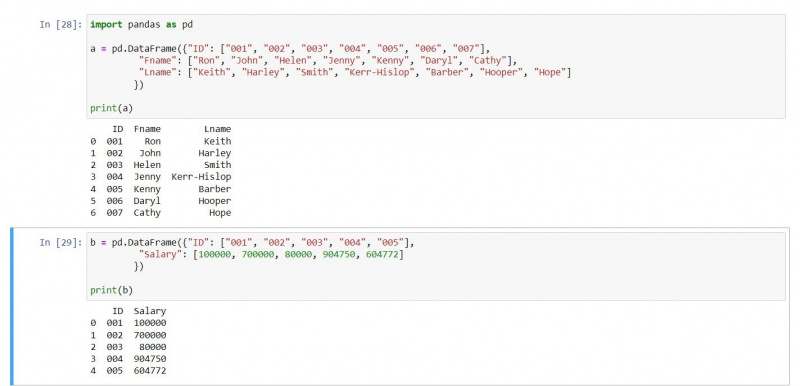
En indre join leverer de matchende poster fra begge DataFrames. Da joinforbindelser bruger indeksnumrene til at matche rækker, returnerer en indre join kun rækker, der matcher. Til denne illustration, lad os bruge følgende to DataFrames:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)Udgangen er som følger:
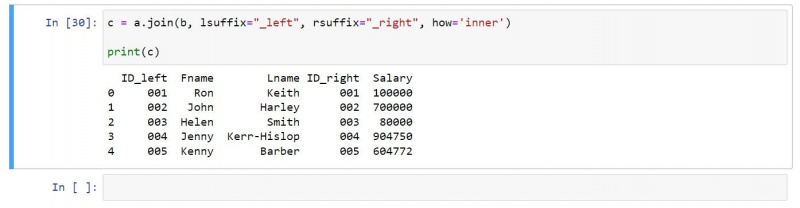
Du kan bruge en indre sammenføjning som følger:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Det resulterende output indeholder kun rækker, der findes i begge input DataFrames:
4. Yderforbindelse
En ydre joinforbindelse returnerer alle værdierne fra begge DataFrames. For rækker uden matchende værdier producerer den en nulværdi på de individuelle celler.
Ved at bruge den samme DataFrame som ovenfor, er her koden til outer join:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)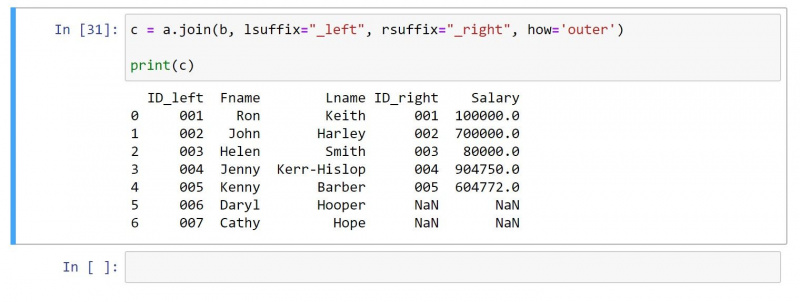
Brug af Joins i Python
Sammenføjninger, ligesom deres modpartsfunktioner, flette og samles, tilbyder meget mere end en simpel joinfunktionalitet. På grund af dens række af muligheder og funktioner kan du vælge de muligheder, der opfylder dine krav.
Du kan sortere de resulterende datasæt relativt nemt, med eller uden join-funktionen, med de fleksible muligheder, som Python tilbyder.